Construindo um Data Warehouse - Conceitos básicos
Construindo um Data Warehouse - Conceitos básicos
Quando me disseram que eu precisaria construir um data warehouse, admito que fiquei um tanto apreensiva. À primeira vista, parecia algo complexo demais. No entanto, à medida que mergulhei nos estudos, percebi que não háum caminho único a seguir. Depende muito das necessidades específicas de cada projeto.
É claro que existem conceitos fundamentais e boas práticas a serem seguidas. Mas, no final das contas, construir um data warehouse pode ser muito menos intimidador do que parece.
Nesta série de posts, pretendo compartilhar alguns insights que adquiri ao longo de muitas horas dedicadas à leitura de livros, artigos, além de experimentar com pipelines e, é claro, cometer alguns erros ao longo do caminho rs
Data Lake vs Data Warehouse: Qual a diferença?
O Data Lake e o Data Warehouse são duas estruturas de gestão de dados distintas, cada uma com suas características únicas.
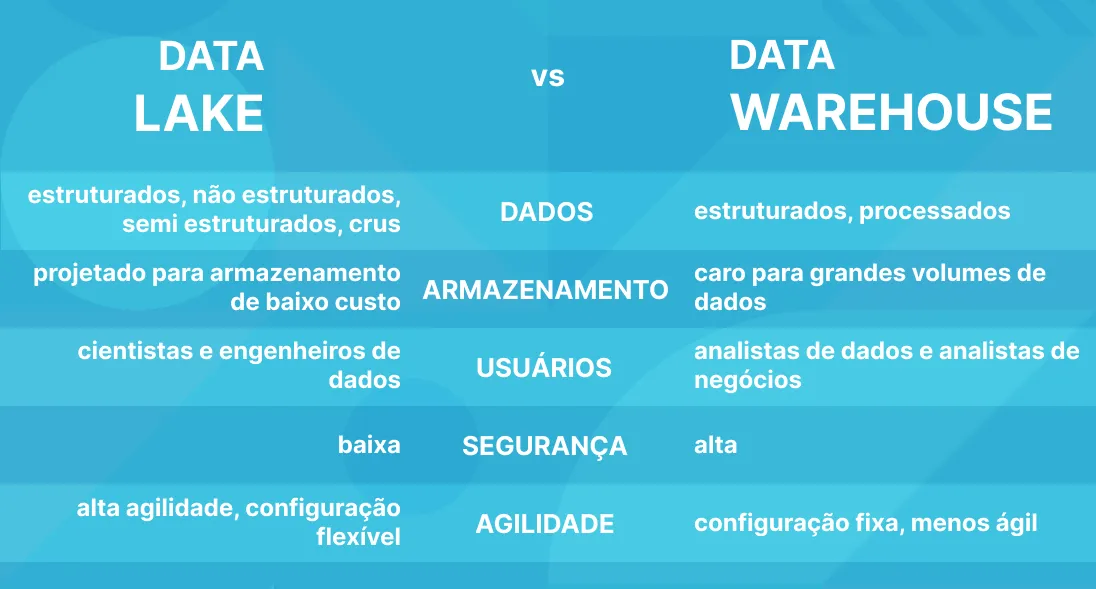
O Data Lake, traduzido literalmente como "lago de dados", funciona como um repositório amplo e vasto, semelhante a um lago onde os recursos são encontrados de maneira não estruturada. Aqui, os dados são armazenados em sua forma original, sem qualquer organização prévia. Essa abordagem permite capturar, armazenar e processar uma grande variedade de dados, sejam eles estruturados ou não. O que quero dizer com isso é que podemos trazer imagens, textos, tabelas e vídeos sem a necessidade organizá-los antecipadamente, o que torna o Data Lake ideal para lidar com grandes volumes de informações brutas.
Em contraste, o Data Warehouse é projetado para organizar e estruturar os dados em conjuntos específicos. Diferentemente do Data Lake, onde os dados são armazenados em sua forma original, no Data Warehouse, eles são organizados de forma padronizada. Isso facilita o acesso e a análise dos dados, mas pode requerer transformações complexas ou pré-definidas antes que os dados possam ser utilizados.
Em resumo, enquanto o Data Lake oferece flexibilidade e capacidade para lidar com uma ampla variedade de dados em sua forma original, o Data Warehouse prioriza a organização e estruturação dos dados para facilitar a análise e o acesso. Cada uma dessas estruturas tem seu papel e é adequada para diferentes necessidades de gestão e análise de dados.
Por que um Data Warehouse?
Muitas empresas lidam com sistemas e bancos de dados que operam em tempo real, conhecidos como OLTP (Online Transaction Processing). No entanto, esses sistemas não são otimizados para lidar com enormes conjuntos de dados e podem levar muito tempo para processar consultas SQL, variando de 30 minutos a algumas horas. Isso resulta em altos custos de execução de consultas devido à falta de otimização.
Os data warehouses na nuvem resolvem esses problemas. Eles pertencem à categoria OLAP (Online Analytical Processing), e populares plataformas como Snowflake, Redshift e BigQuery podem consultar até um bilhão de linhas em menos de um minuto.
Conceitos principais
Nos data warehouses, há três transformações de dados predominantes:
- Integração: Funciona como um ponto de encontro para dados de diversas fontes, incluindo APIs e bancos de dados.
- Limpeza: Os dados provenientes de várias fontes são depurados antes da consolidação, garantindo a confiabilidade deles.
- Refinamento: Os dados depurados de diversas fontes são combinados e processados para extrair informações valiosas.
Integração
Quando falamos sobre integração de dados, estamos essencialmente reunindo informações de diferentes fontes e as colocando em um único local, como um data warehouse. Isso é como juntar peças de um quebra-cabeça para formar uma imagem completa.
Imagine que você está organizando uma festa e precisa reunir todas as informações dos convidados, como nome, telefone e endereço, de diferentes listas de convidados. Integrar essas listas seria como criar uma lista mestra, onde todas as informações estão centralizadas.
A integração de dados é importante porque nos permite ter uma visão completa e abrangente de todas as informações relevantes em um único lugar. Isso facilita a análise e a tomada de decisões mais informadas.
Limpeza
Limpar dados é como fazer uma faxina em uma casa bagunçada. É o processo de identificar e corrigir erros, inconsistências ou duplicatas nos dados, para garantir que eles estejam precisos e confiáveis.
Pense em um conjunto de dados como uma lista de contatos em seu telefone. Às vezes, pode haver números duplicados, nomes mal escritos ou informações ausentes. Limpar esses dados seria como organizar sua lista de contatos, removendo os duplicados, corrigindo erros e preenchendo as lacunas.
A limpeza de dados é importante porque dados sujos ou inconsistentes podem levar a análises incorretas e decisões erradas. Portanto, é essencial garantir que os dados estejam corretos e confiáveis antes de usá-los para análise.
Refinamento
Refinar dados é como lapidar uma pedra bruta para revelar sua verdadeira beleza. É o processo de transformar dados brutos em informações úteis e acionáveis.
Voltando ao exemplo da festa, depois de integrar e limpar as listas de convidados, você pode querer fazer algumas análises, como quantas pessoas estão vindo de cada cidade ou quantos convidados têm mais de 18 anos. Isso seria o refinamento dos dados.
O refinamento de dados é importante porque nos permite extrair insights valiosos e identificar padrões significativos nos dados. Isso nos ajuda a entender melhor o que os dados estão nos dizendo e a tomar decisões mais informadas e estratégicas.
Em resumo, a integração, limpeza e refinamento de dados são processos essenciais no ciclo de vida de um data warehouse, garantindo a disponibilidade de dados precisos, confiáveis e acionáveis para análises e tomada de decisões informadas.